

")
Seeking accurate information from large language models (LLMs) like ChatGPT carries a potential risk – the generation of fabricated "facts." A recent incident involving a New York lawyer highlighted the susceptibility of LLMs to produce false information, termed as hallucinations, even when trained on extensive factual data.
Hallucinations tend to occur when LLMs generate text on unfamiliar topics or inadvertently mix information from diverse sources. In the lawyer's case, ChatGPT conjured imaginary judicial opinions and legal citations, leading to dissatisfaction from the presiding judge.
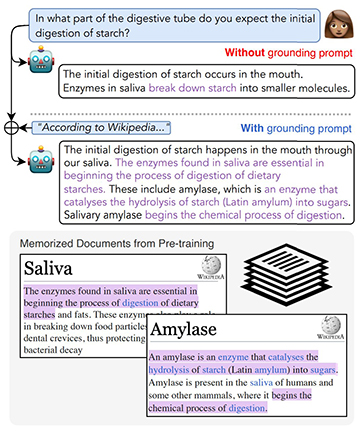
In an effort to mitigate such occurrences, a team of researchers, including doctoral candidates Orion Weller and Nathaniel Weir, developed a method inspired by a common journalistic phrase. The researchers introduced the use of the words "according to" in LLM queries to assess its impact on response reliability.
The study revealed that prompts incorporating "according to" effectively guided language models to ground their responses in previously observed text. Instead of generating false information, the models were more inclined to quote the requested source directly, akin to journalistic practices.
Orion Weller explained, "Language models are really good at following syntactic and semantic cues. Since 'according to' is more likely to occur online when a news article quotes a source, an LLM may take the prompt as a clue to search specifically for quotations from its training data."
Using Data Portraits, a tool developed by the team, the researchers assessed whether an LLM's responses could be traced back to its original training data. The resulting metric, termed "QUIP-Score" (quoted information precision), increased by 5% to 15% when grounding prompts like "According to Wikipedia..." were employed.
The team aimed to enhance knowledge grounding by encouraging LLMs to quote directly from trusted resources encountered during training. By leveraging high-quality sources, the researchers sought to improve the accuracy and detail of the models' responses.
Notably, the "according to" prompting technique proved effective across various LLMs, requiring no human adjustments. The team suggested its optimal performance with larger models and in conjunction with instruction tuning, where models are trained with specific instructions in addition to typical question-answer pairs.
Despite the success of the technique, the researchers emphasized the importance of acknowledging that the generated text's presence in a source like Wikipedia doesn't automatically guarantee its correctness. They also highlighted the dependence on the quality of the data the model was trained on, and they implemented filters to exclude information from unreliable websites.
In conclusion, while the method isn't a definitive solution, it represents a step towards improving the factual accuracy of LLM-generated information, leveraging insights from their training data.
